Snowflake与现代数据栈
2021 年已经没有人谈大数据这个概念,不是它失败了,恰恰是因为它成功了。成功技术的吊诡之处在于,它最终会被认为是理所当然,消失在背景音中。
「现代数据栈」是否成立并不取决于技术本身,而是背后更大的前置条件——市场是否接受公有云。比如对于国内的云厂商来说,是满足客户眼下更迫切的需求,帮助他们上私有云,甚至部署 on-prem,还是坚持公有云策略,依旧是个没有结论的话题。
Snowflake 的战略就是 All-in 公有云,事实上 All-in 本身就是 Mike Speiser 一以贯之的投资孵化策略,至少在 2012 年的美国,绝大部分公司和投资者都相信如果你想把产品销售给大客户,就必须支持 on-prem。Snowflake 真正走向成熟是 2017、2018 年,在此之前所有「现代数据栈」上的创业公司又何尝不是一种 All-in?
联想到了张一鸣最近对 All-in 的看法,他们的 All-in 显然不是偷懒,相反是有原则的体现。Reid Hoffman 说过,原则是你明知代价高昂的情况下仍旧坚持,这里的前提便是它并非来自于「无知者无畏」。他们 All-in 的不是公有云会不会到来,而是公有云是否会很快到来。
事后来看,在一个公有云和 SaaS 发展更快的市场里,数据基础设施已经发生了剧烈的变化。以下是我从行业先锋、资本、工作流和创业公司这些角度看到的一些痕迹。
S-曲线
让我们先从 The Modern Data Stack: Past, Present, and Future 开始,了解「现代数据栈」从哪里而来。作者 Tristan Handy 是 Fishtown Analytics 的创始人,除了数据建模工具 dbt 创造者的这个身份,他也是一名有 20 年从业经验的分析师。
去年上市的 Snowflake 让很多人知道了 Cloud Data Warehouse(CDW),但很少有人知道,作为第一个云原生数据仓库 Redshift (2012) 才是这个故事的起点。Redshift 中的 Red 指的就是 Oracle,从 Oracle 转移的意思。
尽管 MPP 是十多年以前就有的技术,事实上当年 AWS 也是拿了别人家的数据库代码改成了 Redshift,但如果不是云计算把 Data Warehouse 的成本从每年 10w 美金降到了每月不到 200 美金,很多人也无法享受到这项技术对工作方式带来的改变。
10-1000x performance increases tend to change the way that you think about building products. Prior to the launch of Redshift, the hardest problem in BI was speed: trying to do relatively straightforward analyses could be incredibly time-consuming on top of even medium-sized datasets, and an entire ecosystem was built to mitigate this problem.
10-1000 倍的性能提升,往往会改变你构建产品的思路。在 Redshift 推出之前,BI 中最难解决的问题是速度:即使是中等规模的数据集,想要做相对简单的分析也会非常耗时,为了缓解这个问题,我们建立了整个生态系统。
新的工作方式意味着新的软件供应商,Redshift 激起的涟漪是 2012 到 2016 之间涌现了一批数据产品,它们结合 Redshift 一起使用,让用户的工作效率大幅提升,共同组成了今天我们看到的「现代数据栈」。
So, for those of us building products in the modern data stack, Redshift was the ocean from which we evolved.
对于我们这些为现代数据栈打造产品的人来说,Redshift 是我们进化而来的海洋。
但过去四年,一切似乎进入了发展的平缓期,Handy 说:「如果你在 2016 年睡了一觉并在 2020 年醒来,会发现整个栈上的东西并没有很大变化。」
他将这种变化速度的放缓与电报机和铁路技术的 S 曲线相比较——每当变革性的新技术在刚出现时,只能够吸引那些对技术更宽容的 early adotper,再被更多人所采纳之前,仍旧需要有不断发生大大小小的事情,来推动用户体验和性能的提升。比如爱迪生在 1874 年发明的 「四重电报机」就曾将西联公司电报线路的吞吐量提升了四倍,而距离第一台电报机发明,已经过去了 30 年。
而过去 4 年这个栈上的产品,无论是用户体验还是可靠性都又有了长足的进步,S 曲线的拐点就在眼下。

三种不同的数据栈
A16Z 去年发布了数据基础设施行业的综述,两年间与数百位创始人、企业数据负责人和专家的交谈,并采访了 20 位一线从业者,拼凑出了更完整的图景。A16Z 的叙事是根据不同的公司规模和用例,绘制出三种新兴数据栈的工程图纸。
虽然看起来是在介绍技术解决方案,其实是在对问题进行抽象和归纳,这是一种 Product/market fit 的叙事,这里的产品是数据基础设施,市场是对这些基础设施有需求的公司。我整理了A16Z 过去两年在相关领域的几笔投资,发现这三份图纸同样也是 A16Z 的行动方案。
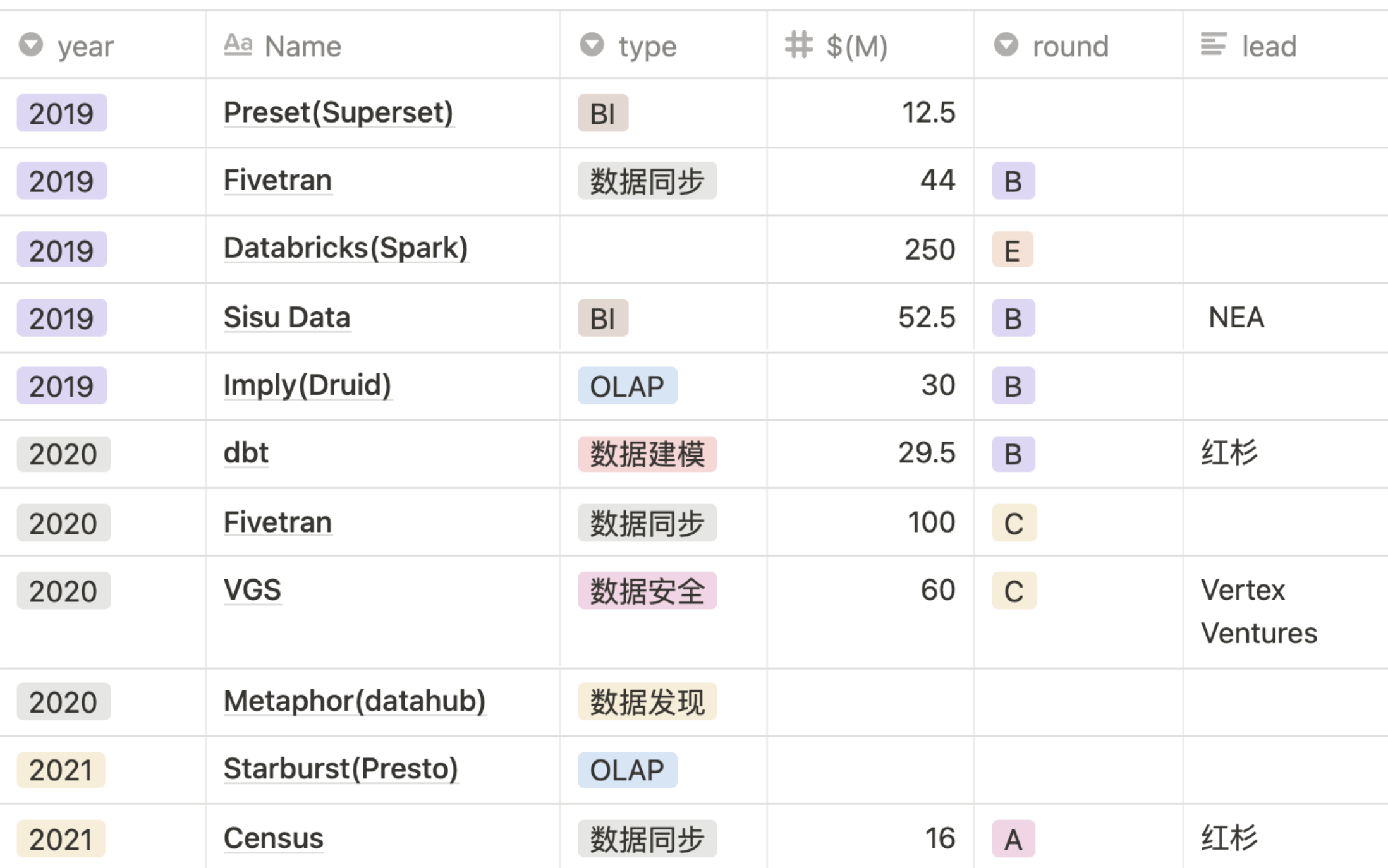
介绍一下这三种架构。
云原生分析栈
也就是「现代数据栈」,其核心用例包括:报告、仪表盘和 adhoc,通常使用 SQL 来分析结构化数据。
这种模式的优势包括:前期投入小,速度快,易上手,需要的人少。围绕 CDW 使用 SaaS 工具,对不同规模大小的公司都很友好,也是从传统数仓迁移到共有云上的方案。
缺点是不太适合有更复杂数据需求的团队,比如数据科学、机器学习或流式应用。
Hadoop 民工栈
从 on-prem 的 Hadoop 大数据架构演化而来,背后一直是几个大厂和开源社区在推动,我把它称为「Hadoop 民工栈」,也是目前即刻所使用的技术栈。
这种架构可以灵活地支持不同的应用、工具、定义的功能和部署环境,而且它对大型数据集具有成本优势。
缺点是维护它需要投入一定的时间、金钱和专业知识,不太适合那些只想做简单分析的公司。虽然国内外云计算厂商一般会为这种架构提供托管服务,但因为各种组件还是需要自己花时间来维护,不太适合人少的数据团队。
机器学习栈
这个栈最大的特点是打通了线上的服务和离线的机器学习,所以也叫 Operational AI/ML,和 DevOps 相似的是,它也将工作生命周期延长到了 operation 的阶段。
和「Hadoop 民工版」相比,它最大优势在于它直接在数据湖上提供分析的能力,避免了存两份完全相同的数据。
分析栈和机器学习栈与其说是两种不同的架构,不如说是两种宗教,一个是辅助人通过使用数据做出更好的决策,另一个是将数据的智能直接输出到面向用户的应用之中。
这两个平行发展的生态未来是否会融合?A16Z 另有两期播客专门讨论这个话题,感兴趣的朋友可以在这篇文章中找到这两期节目的链接。
工作流的变化
从 ETL 到 ELT
A Snowflake deep dive 解释了为什么 CDW 彻底改变了人们的工作方式。虽然这里将直接引述文章的结论,跳过技术上的细节(比如维度、Cube),但我强烈推荐阅读原文,因为花费时间去了解这些细节才能理解从 ETL 向 ELT 转变的深刻原因。
Before the cloud era, data warehouses were built on-premise and had to run on a single system that had to be incredibly powerful (lots of cores, memory and storage). Because the total resources of the hardware were fixed, users had to play lots of tricks to do more [analysis] with less [compute & memory].Why is it so hard to work with data warehouses? Let’s dive a little deeper, just to understand the difficulties that users faced. […]
在云时代之前,数据仓库是建立在企业内部的,必须运行在一个系统上,这个系统必须非常强大(大量的核心、内存和存储)。因为硬件的总资源是固定的,所以用户不得不玩很多花样,用更少的【计算和内存】做更多的【分析】。 为什么数据仓库的工作这么难?为了解用户面临的困难,让我们深入了解一下。[…]
而这些花样带来了巨大的人力成本,它给分析工作带来了掣肘:
During the initial ETL stage, analysts had to refine the raw data into a specialized format that restructures the data, in order to make it more ideal for extracting insights in the dimensions (business objectives) they cared about. The severe downsides to this was that it forced analysts to have to make a lot of upfront assumptions, which in turn made the entire process extremely inflexible. If those assumptions were wrong (“oh wait, the VP of Sales wants to see this data summed up by region, not by state”), they would have to start all over. Once the dataset was in the data warehouse, they would have to further refine the data to create highly-honed OLAP Cubes, which allowed them to do deeper multi-dimensional analysis. Again, these tricks were all employed due to the constraints of having the database be on hardware with capped resources. I cannot stress enough what a royal pain in the ass this whole process was!
在最初的 ETL 阶段,分析师必须将原始数据预处理为专门的格式,对数据进行重构,在他们关心的维度上(业务目标)获得洞察。这样做的严重弊端是,它迫使分析人员不得不做出大量的前期假设,使得整个过程变得极其不灵活。如果这些假设是错误的(哦,等等,销售副总裁希望看到这个数据按地区,而不是按州来汇总),他们将不得不重新开始。一旦数据集进入数据仓库,他们就必须进一步完善数据,创建深度定制的 OLAP Cubes,从而进行更深入的多维分析。同样,之所以用这个技术,都是由于数据库的硬件有资源上限导致的。 我怎么强调都不为过,这整个过程是多么痛苦。
Extract(E) 和 Transform(T) 的分离催生了一批新的创业公司,因为 E 在不知道业务逻辑的情况下,可以专注于自动化和对接不同的数据源。T 在不用考虑数据源是什么的情况下,可以专注于代码的复用和开发流程。
数据工程师/分析师的崛起
红点创投的合伙人 Tomasz Tunguz 认为未来 10 年是数据工程师的十年。
今天一个很重要的趋势是 IT 的「消费化」,越来越多的员工以消费者的身份在市场上选择流行的技术,然后将其引入工作场合。
比如现代化的营销团队会为自己购买数据产品,一开始只有一些仪表盘——有多少新的线索?有多少广告支出?当他们无法忍受等待其他部门同事「拉数」的时间,就会在团队内部建立自己的数据团队,雇数据分析师和数据工程师来帮助他们更快速地了解问题的答案。把这里的营销团队换成产品、销售团队也一样成立,所有人都需要在他们想要的时候准确地得到数据。
CDW 虽然解决了唯一数据源的问题,但在它之上,人们使用不同的工具谈论和使用数据,带来了新的挑战,如何确保数据的一致性和可靠性?
例如营销团队从销售团队那里访问 CRM 的数据,来了解客户价值,从产品团队那里得到客户的转化漏斗,从财务团队获取计费的数据,从客户支持那里了解客户的生命周期。
Tunguz 列举了一些他在研究这个领域时在不同企业身上看到的相同问题:
Each team has their own tools, data storage depots, and infrastructure. It’s basically a big bucket of Legos. Systems don’t talk to each other, there’s confusion about the three different definitions of revenue across three different departments, nobody can find the data, where’s the customer support data table.
每个团队都有自己的工具、数据仓库和基础设施。基本上就是一个大桶的乐高玩具。1)系统之间互不沟通,2)三个不同部门对收入有三种不同定义,很混乱,3)谁也找不到数据,4)客服数据表在哪里。
数据工程师的工作不仅仅是把数据移动到需要它们的地方,而需要像软件工程师一样,用一套规范和高效的流程来管理基础设施,确保数据准确性和一致性,像发布软件一样发布数据。这是一门新的学科,而今天绝大多数公司,还没有这个概念。
反向 ETL
反向 ETL(reverse-ETL) 是最近比较流行的一个词,这项技术实现了数据从 CDW 到 SaaS 的馈送,利用 CDW 中的数据提高运营的效率。
反向 ETL 是 Tomasz Tunguz 提到的第一类数据反馈循环 (灰线),而未来有可能出现第二类反馈循环 (红线):
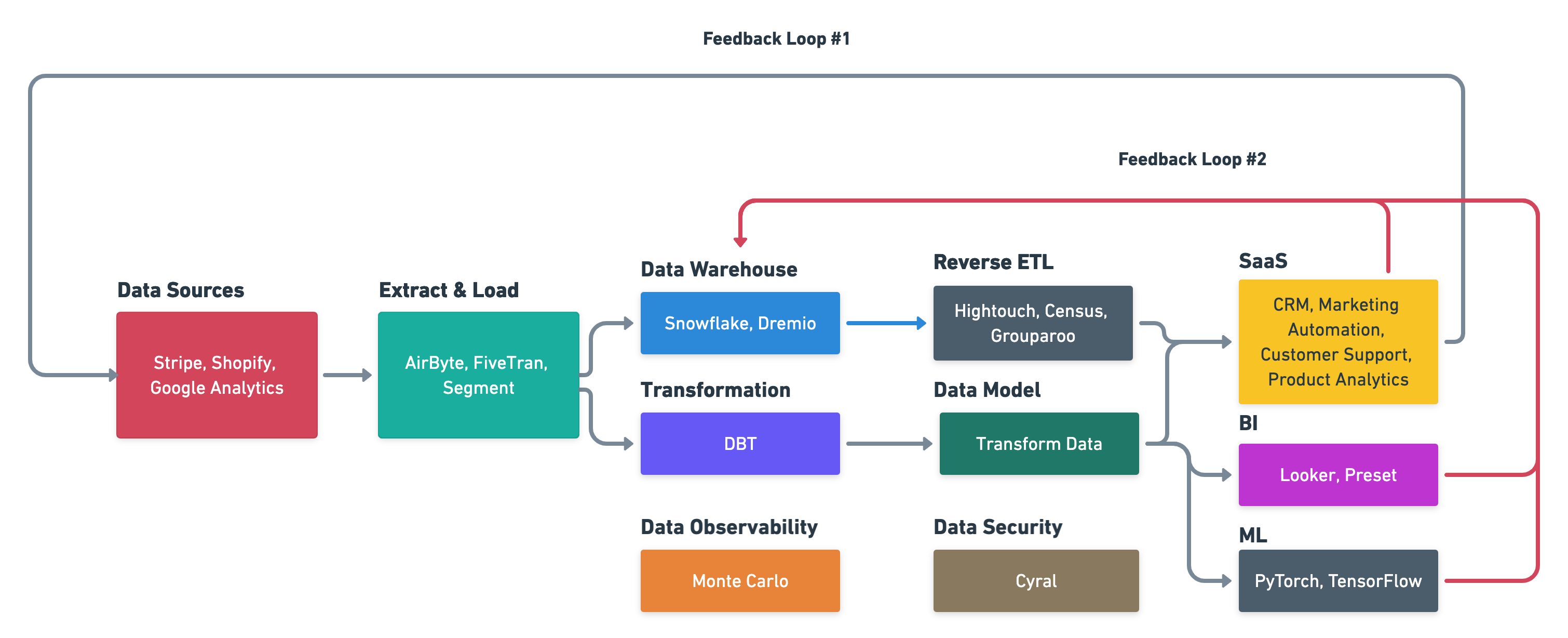
The second feedback loop outputs data products and insights that are then fed into the data warehouse layer for downstream consumption, perhaps in the form of dashboards in SaaS applications or machine learning models and associated metadata. SaaS applications also write back to the CDW directly.
在第二类反馈循环中数据并非通过 ETL 从 SaaS 流到 CDW,而是某种物化后视图直接写入,换言之,未来的 SaaS 在设计架构时就将考虑到 CDW 的存在,这会促进更多的 SaaS 将数据推送到 CDW,形成一种循环。
Tristan Handy 也有相同观点,像 Google Analtics 这样的事件分析工具,未来也可以基于 CDW 直接搭建,它把这类 SaaS 称为垂直化分析。
下一个伟大平台
CDW 除了给使用它产品的客户带去了价值,事实上它的平台化属性,也为围绕「现代数据栈」打造产品的创业公司赋予了新的机会。
在 Why Snowflake could be the next Great Platform 中,Vinzelles 指出了 Snowflake 将成为下一个伟大平台的原因:
CDWs are adopted by both mature and immature data organizations because they are versatile, performant, inexpensive, scalable, easy to setup and to use. Companies use them to centralize and unify their data, becoming their de facto cloud-native source of truth for their data.
CDW 被成熟和不成熟的数据组织所采用,因为它们具有多功能、高性能、廉价、可扩展、易于设置、易于使用的特点。公司使用它们来集中和统一数据,成为「事实上」的云原生唯一标准数据源。
CDW 改变了企业收集与统一数据的方式,创业公司只需要接入几家主流 CDW,以 SaaS 的形式提供服务,专注在自己核心的价值主张上,然后迅速成长并吸引到资金。2016 年以来围绕「现代数据栈」创业公司大多采取了免费增值或开源的 go-to-market 战略,而为 on-prem 数仓提供第三方技术供应商,一般通过销售团队获客,所以成本很高。
SaaS 的另一个优势是销售和部署的周期很短,用户被价值主张所吸引,登陆主页后,花几分钟部署就可以体验产品,并决定是否要购买了。迭代速度也更快,因为不管有多少客户,SaaS 背后都只有一套系统,随时能够发版。